SOOTHER Synthesis
Here are some examples of SOOTHER’s synthesised whisper in training and inference. The “training” samples are output at “checkpoints” during model training and are derived from the speech dataset; the “inference” samples are created by querying a trained model with text that is not included in the speech dataset. As you can see below, the “training” samples are far more coherent because the algorithm has contextual information about the text being output.
As noted, SOOTHER is trained imperfectly, and this failing is clear, in particular, in the “inference” samples. For more about training and inference, see the general discussion on the subject.
I completed two major rounds of training on SOOTHER, one to ~250,000 steps, and another to ~140,000 steps, which was halted due to time; budget; and a creeping suspicion that my data was malformed and should be sanitized further before continuing.
Training Round One
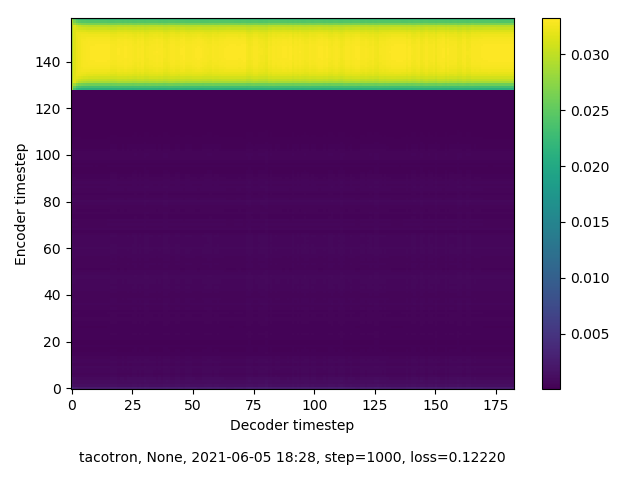
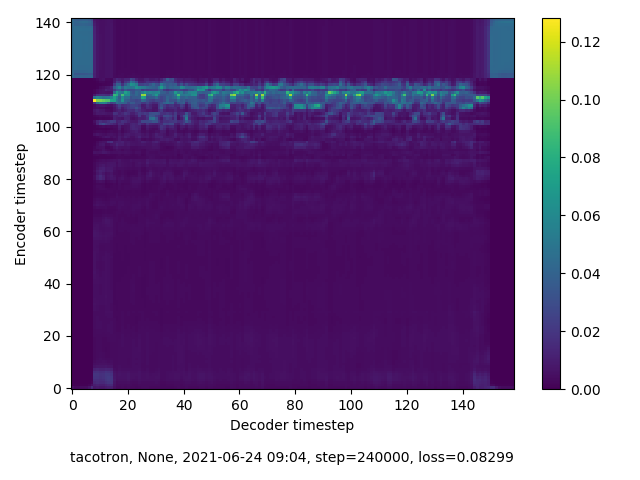
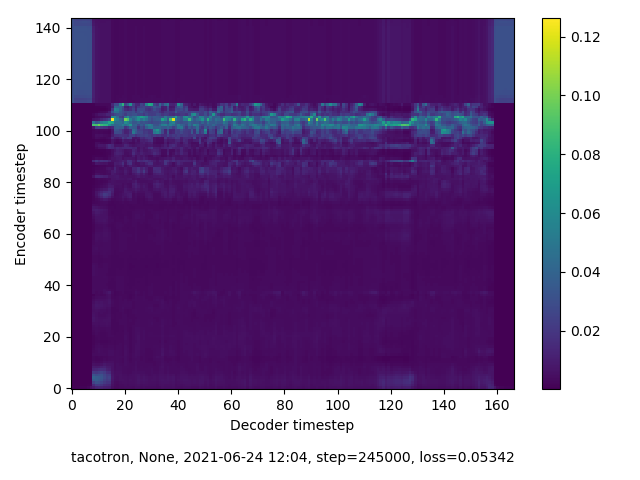
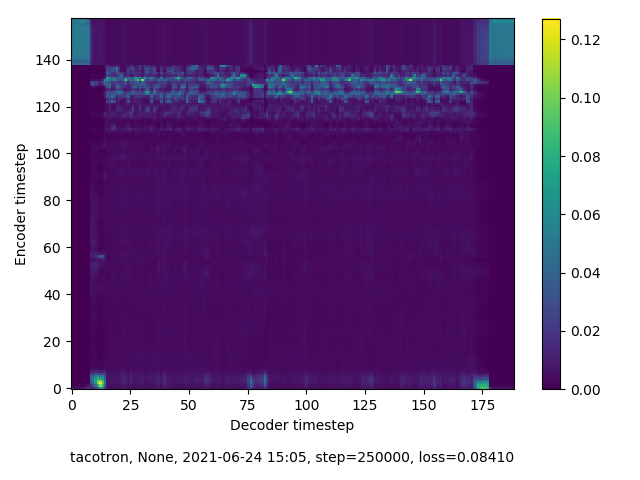
This round of training was undertaken without having exactly “RTFM”’d. As a result, I had no idea what I was suppossed to be observing in the spectograms that are generated along with audio samples at training checkpoints. Spoiler: I wasn’t seeing the right thing. Although checkpoint audio samples improved over time , the accompanying spectrograms indicated that my model was not finding alignment. This becomes apparent when attempting inference on this model, which I demonstrate in the next section.
1,000 steps
240,000 steps
245,000 steps
250,000 steps
Inference Round One
Here, you’ll see the catastrophic failure in inference. Although inference also largely fails for the model trained in round two, here, the output from inference is completely incoherent.
Inference at 240,000 steps - 1
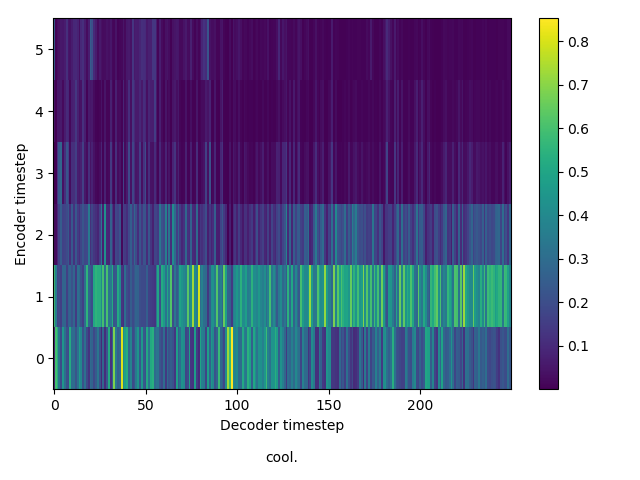
Inference at 240,000 steps - 2
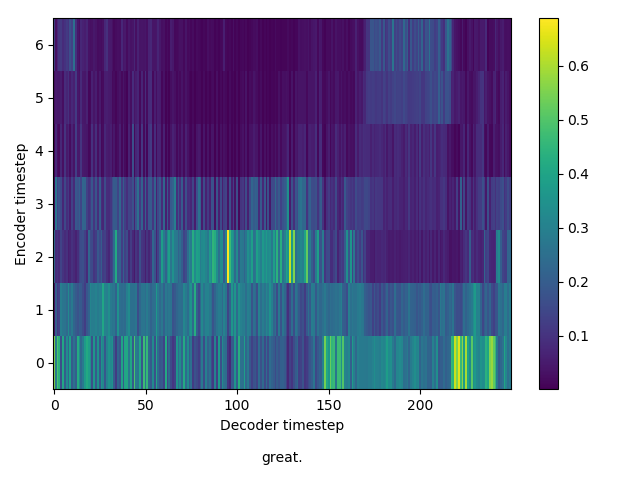
Training Round Two
In this round of training, my model quickly reached something like alignment, although it remains imperfect. The “alignment” line does not run straight, without break, and directly from SW to NE corner of the spectogram. However, the near-alignment achieved in this round of training means that inference performed on this model sees greater success than in the previous round.
20,000 Steps
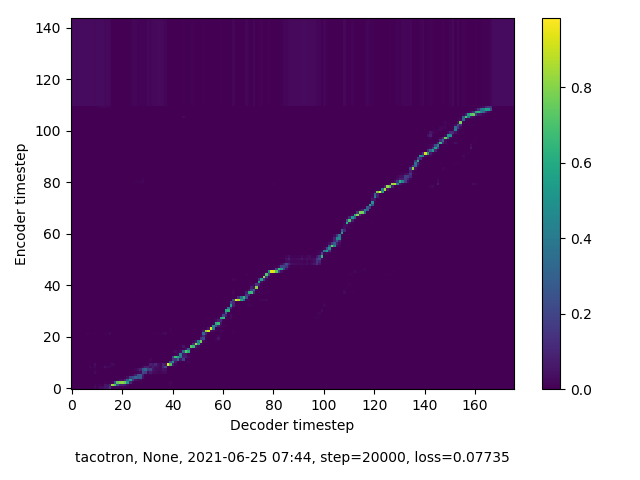
40,000 Steps
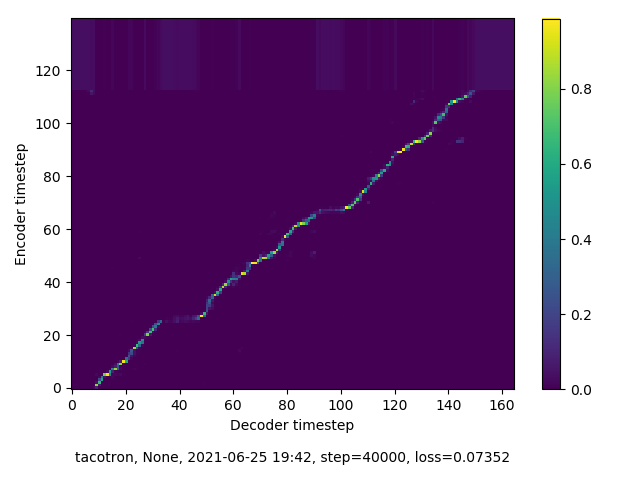
58,000 Steps
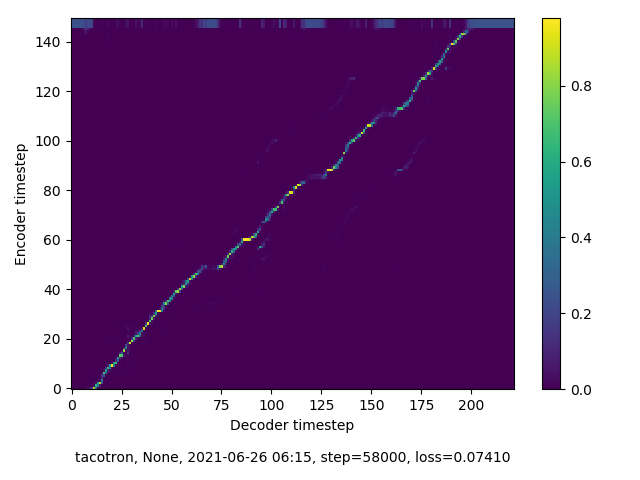
140,000 Steps
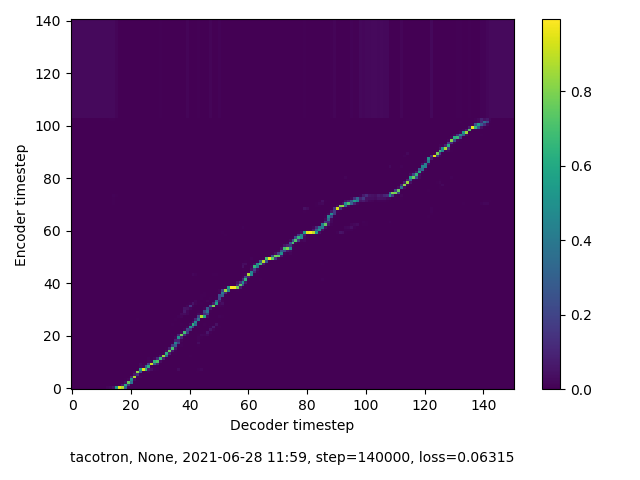
Inference Round Two
Here, SOOTHER’s voice becomes more coherent, but there are still many problems, including:
- The “stop” intuition is missing; all audio files are the same length and contain many seconds of silence at the end or an echoing noise
- The pacing is off – the algorithm doesn’t understand how to pace its speech
- As a result of the above, words collapse, expand, and get snuffed out.
61,000 Steps
168,000 Steps
In conclusion, SOOTHER doesn’t really know how to speak yet, but SOOTHER yet will speak :)