Training and Inference Hardware
n.b. this post might seem completely inane but I couldn’t find information about AWS machine specs for tacotron-derived speech synthesis anywhere so I’m writing it in the hope that it helps someone in the future.
To train SOOTHER on AWS, I used the following machines:
- p3.2xlarge
- p3.8xlarge
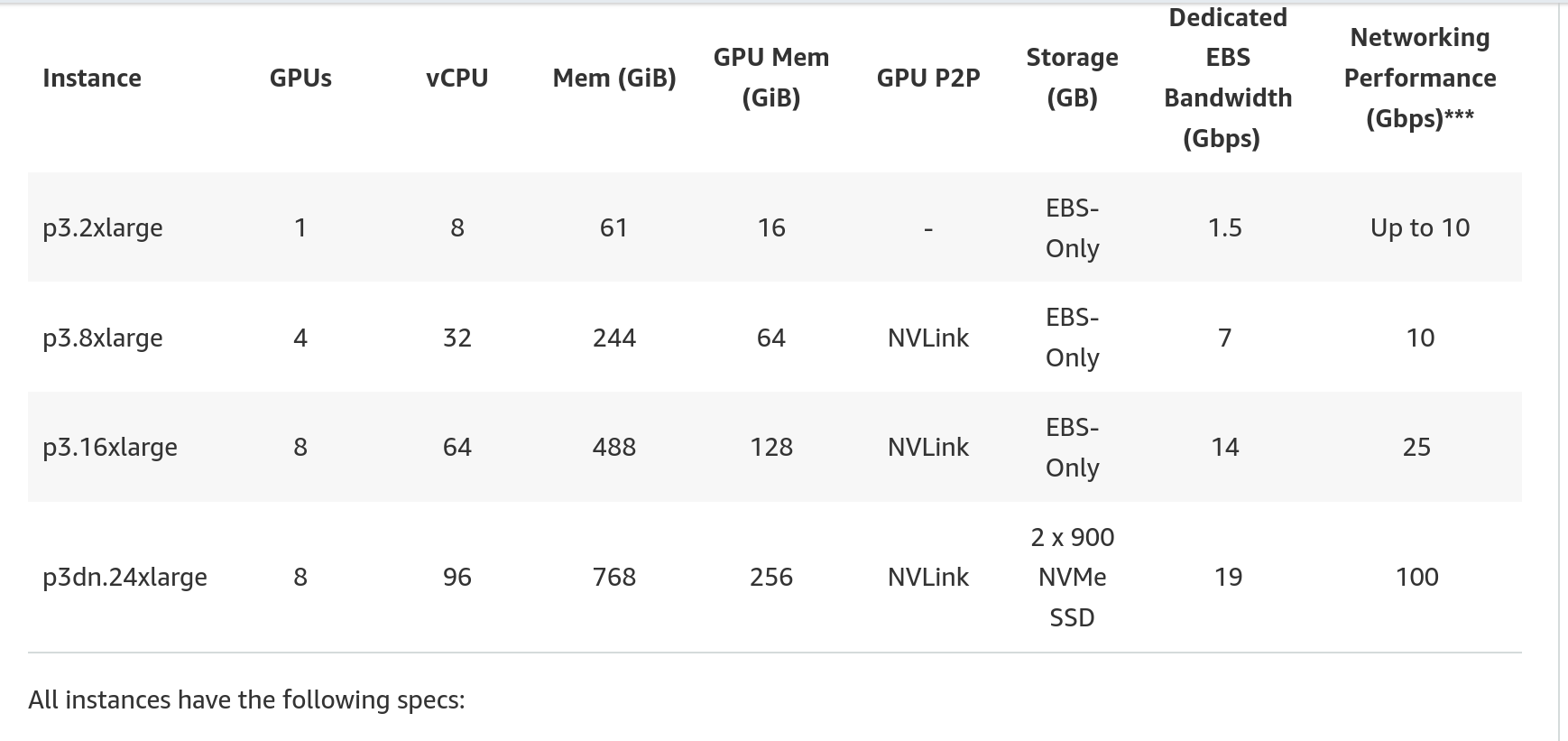
I was able to obtain a p3.2xlarge instance without issue, although I did have to request that AWS increase the vCPU allownance on my account, which they did promptly. However, it took 4+ days to be approved for the p3.8xlarge because of the significantly larger GPU/vCPU load. I had to submit detailed information about my project and my intended usage of the instance, which was interesting.
The p3.8xlarge is significantly more expensive, clocking $15.92/hr versus the $3.82/hr of the p3.2xlarge. By the time I was approved for the p3.8xlarge, I had already run through much of my training budget – and 3 hours of run-time on the p3.8xlarge showed me that it was not exponentially faster than the p3.2xlarge, which I had expected it to be. I was clocking about ~2 seconds a step on the p3.2xlarge, and the p3.8xlarge reduced this to about 1.3 s/step. This didn’t justify the added expense of the instance. It could be that I had something improperly configured in my training setup that was preventing me from taking advantage of the more powerful hardware; I simply don’t know enough about this.
Any way, I ended up doing the vast majority of my training on the p3.2xlarge, running an instance for a total of 370 hours. This enabled me to train different models for a total of about 450,000 steps.
Because inference was still failing in the second round of training, I did not fully implement a Text-to-Speech server to query the model. However, were I do this in the future, I would consider trying something like elastic inference or elastic GPUs to handle inference requests in testing and beta. This seems like it would probably be more affordable than constantly running a p3.2xlarge server, the accumulated costs of which are non-trivial.